Gireg Lanoë, Acsystème
[01:22] Bonjour à tous, Gireg Lanoë. Je suis ingénieur d’études chez Acsystème. Je vais vous présenter le sujet avec en première partie une présentation du problème, du contexte, l’étude qui a été réalisée avec Matlab, Simulink, les outils qu’on a déployés pour aider PSA et enfin la conclusion.
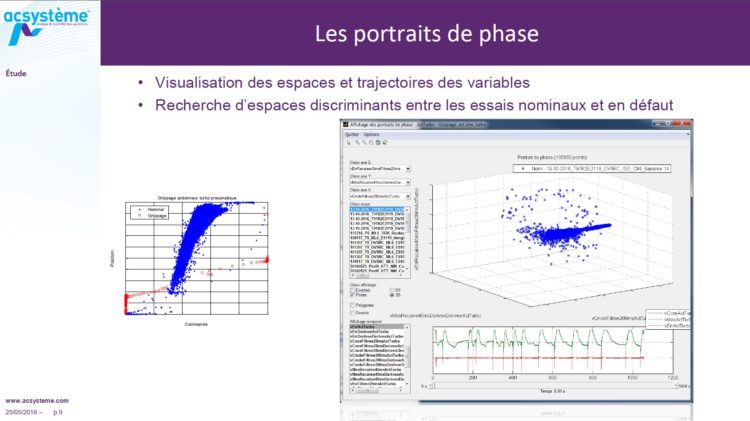
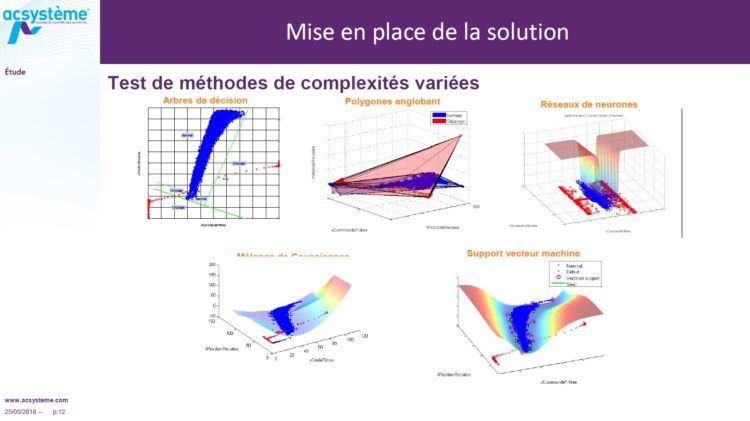
La première partie : le contexte, c’est le diagnostic ! Qu’est-ce que c’est le diagnostic ? Sur un moteur, on a des consignes qui sont envoyées par le conducteur, c’est-à-dire qu’il accélère, il freine, il passe les rapports. Le diagnostic : le moteur, lui, reçoit des messages des capteurs. Et le diagnostic consiste à analyser les potentielles incohérences qu’on peut avoir entre ce qui a été envoyé, ce qui est demandé au moteur et ce que le moteur réalise réellement. Et si on a un écart en fonction de la gravité du défaut, on aura différents types de voyants qui pourront s’allumer sur le tableau de bord et qui seront également visibles en concession. L’enjeu pour le diagnostic moteur, c’est de réduire le nombre de déposes en service après-vente, notamment dans les phases de garantie. L’intérêt est clair pour le constructeur puisque dès qu’on est capable d’identifier la panne, on va être capable de réparer le bon composant et donc faire une intervention rapide. Et également la satisfaction client : si le client a besoin de faire plusieurs allers-retours avec le garage, on peut penser que la satisfaction va baisser. Donc tout l’enjeu, c’est d’améliorer la qualité des diagnostics moteurs, avec notamment une identification plus précise de la source, de façon à réduire le temps d’intervention et un bon compromis de détection. C’est-à-dire qu’une méthode de détection, ce sera toujours un compromis entre de la non-détection et de la fausse anomalie. La non-détection, le risque, c’est qu’on ne détecte pas le jour où le composant casse : « On est arrêté sur le bord de la route ». Et la fausse anomalie, elle, à l’inverse, elle va faire ce qu’on appelle « l’effet sapin de Noël ». C’est-à-dire que sur le tableau de bord du véhicule, le voyant va s’allumer de manière intempestive alors qu’en réalité, il n’y a pas de défaut.